elasticsearch6.x倒排索引和分词
摘要
倒排索引(Inverted Index)也叫反向索引,有反向索引必有正向索引。通俗地来讲,正向索引是通过key找value,反向索引则是通过value找key。
倒排索引(Inverted Index)也叫反向索引,有反向索引必有正向索引。通俗地来讲,正向索引是通过key找value,反向索引则是通过value找key。
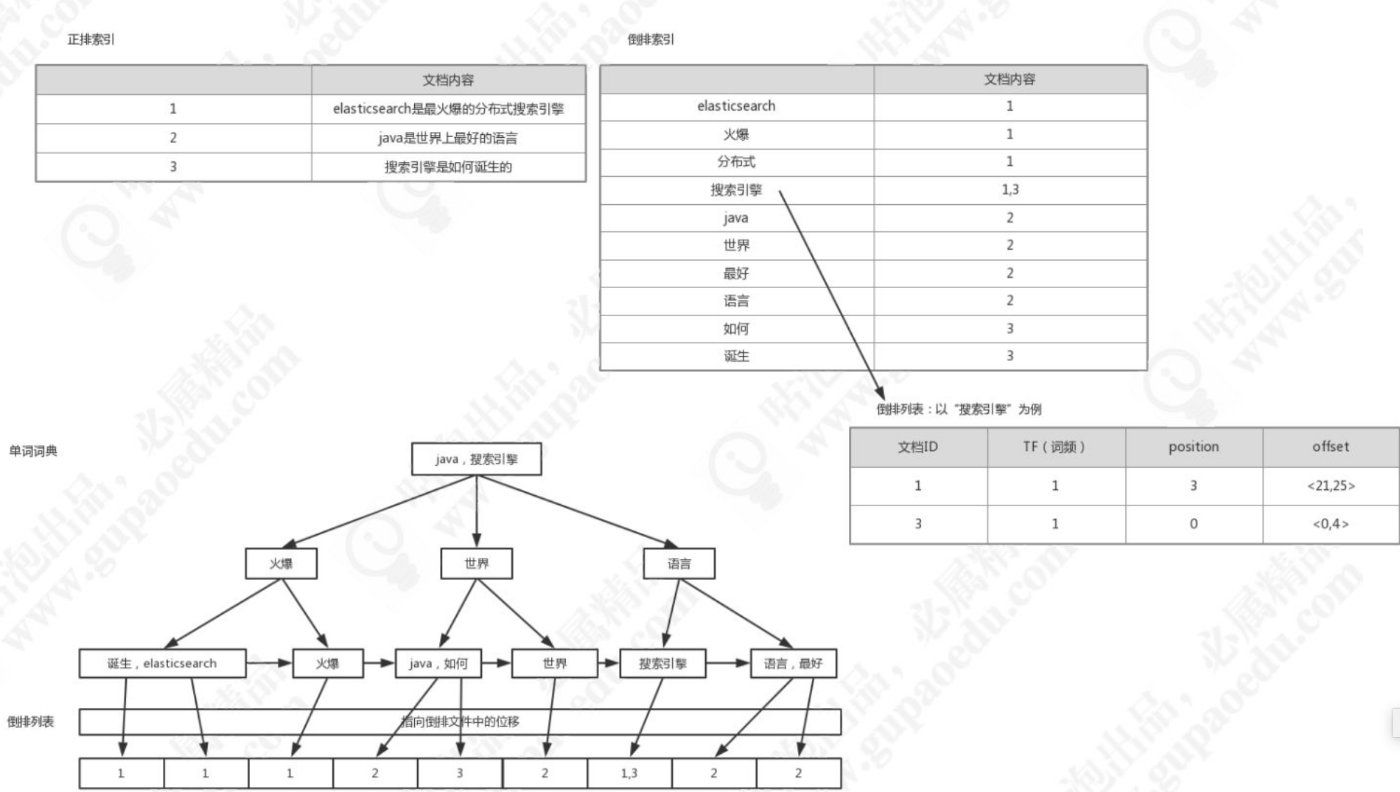
倒排索引
- 正排索引:文档id到单词的关联关系
- 倒排索引:单词到文档id的关联关系
示例:
对以下三个文档去除停用词后构造倒排索引
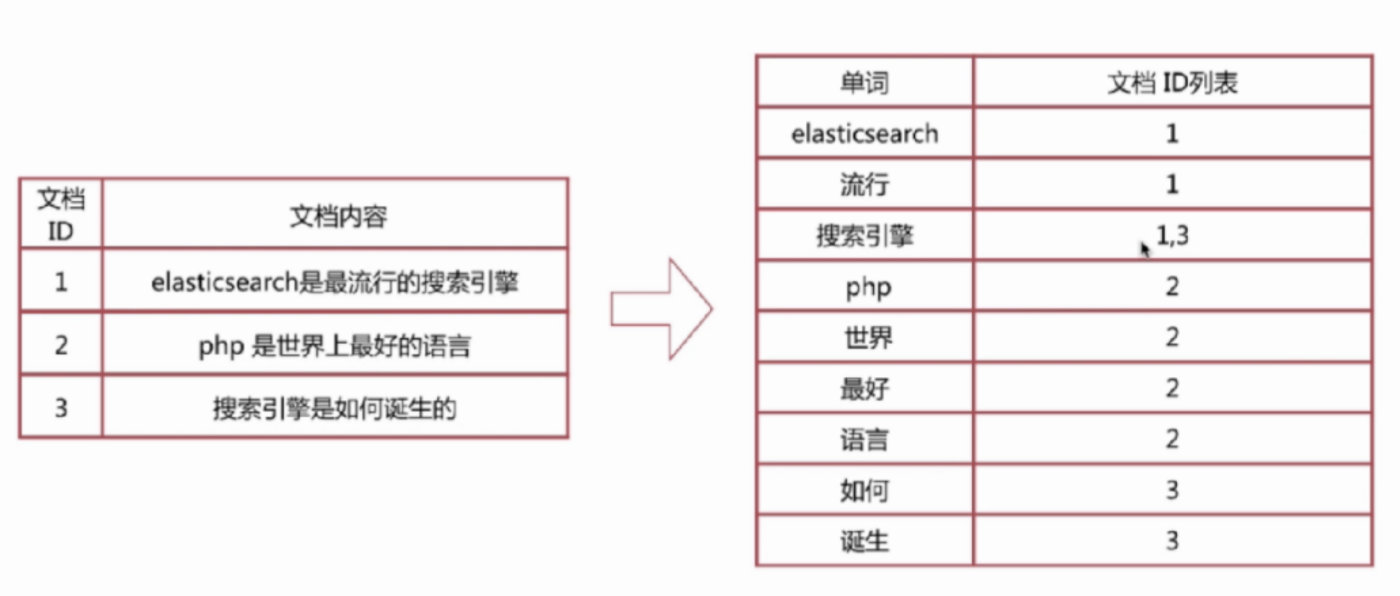
倒排索引-查询过程
查询包含“搜索引擎”的文档
- 通过倒排索引获得“搜索引擎”对应的文档id列表,有1,3
- 通过正排索引查询1和3的完整内容
- 返回最终结果
倒排索引-组成
- 单词词典(Term Dictionary)
- 倒排列表(Posting List)
单词词典(Term Dictionary)
单词词典的实现一般用B+树,B+树构造的可视化过程网址: B+ Tree Visualization
关于B树和B+树
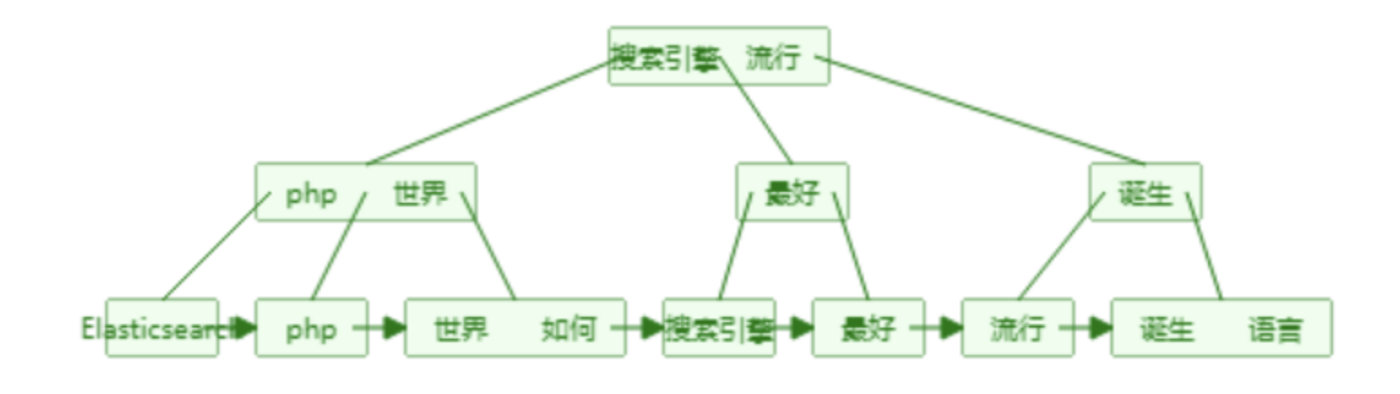
倒排列表(Posting List)
倒排列表记录了单词对应的文档集合,有倒排索引项(Posting)组成
倒排索引项主要包含如下信息:
- 文档id用于获取原始信息
- 单词频率(TF,Term Frequency),记录该单词在该文档中出现的次数,用于后续相关性算分
- 位置(Posting),记录单词在文档中的分词位置(多个),用于做词语搜索(Phrase Query)
- 偏移(Offset),记录单词在文档的开始和结束位置,用于高亮显示
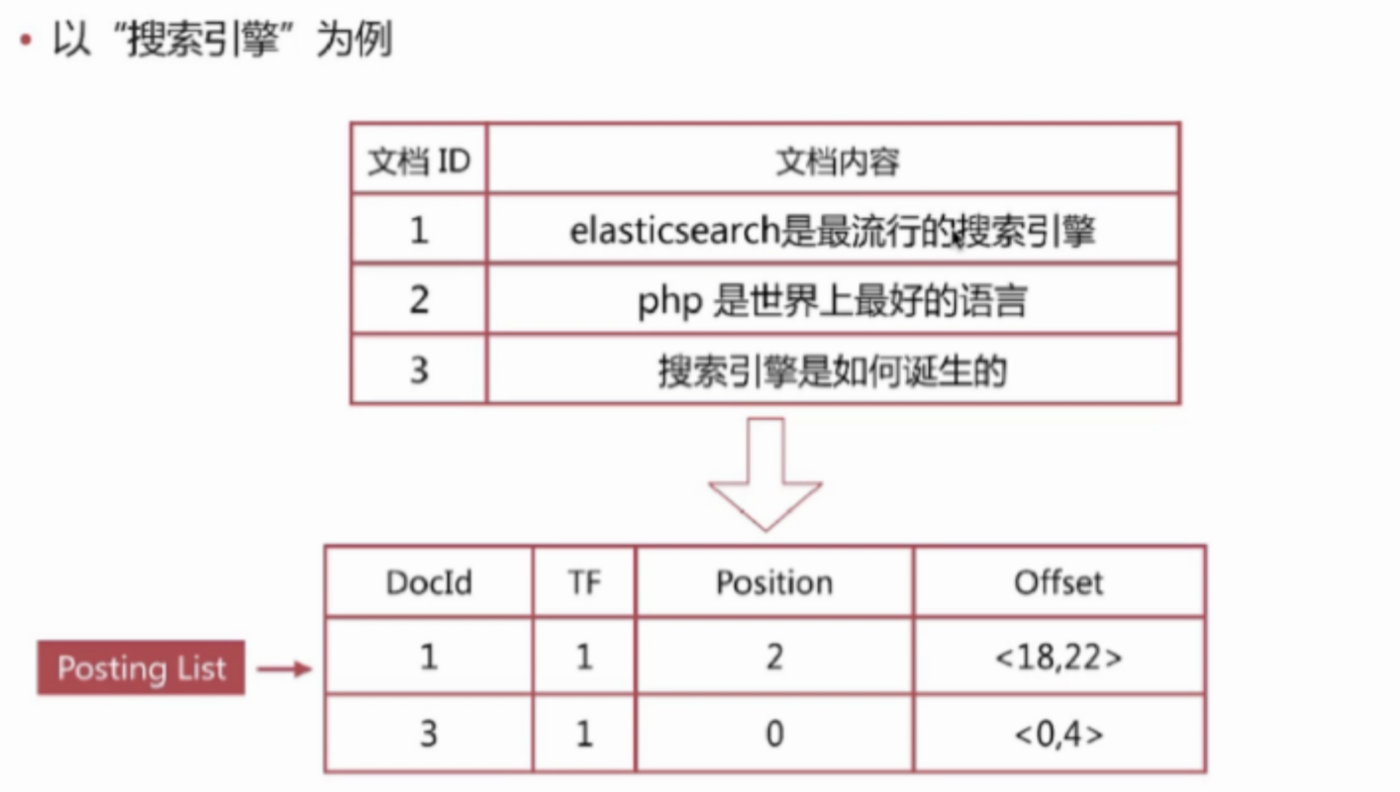
B+树内部结点存索引,叶子结点存数据,这里的 单词词典就是B+树索引,倒排列表就是数据,整合在一起后如下所示
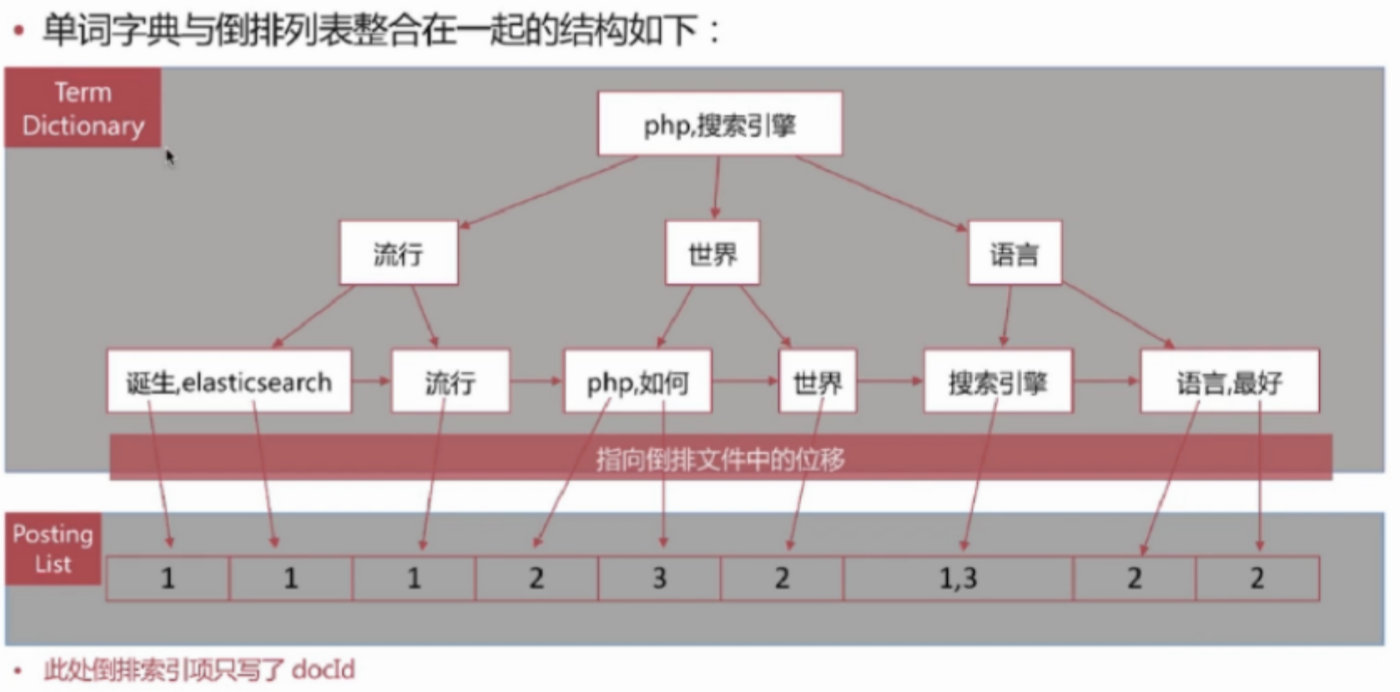
ES存储的是一个JSON格式的文档,其中包含多个字段,每个字段会有自己的倒排索引
分词
分词是将文本转换成一系列单词(Term or Token)的过程,也可以叫文本分析,在ES里面称为Analysis

分词器
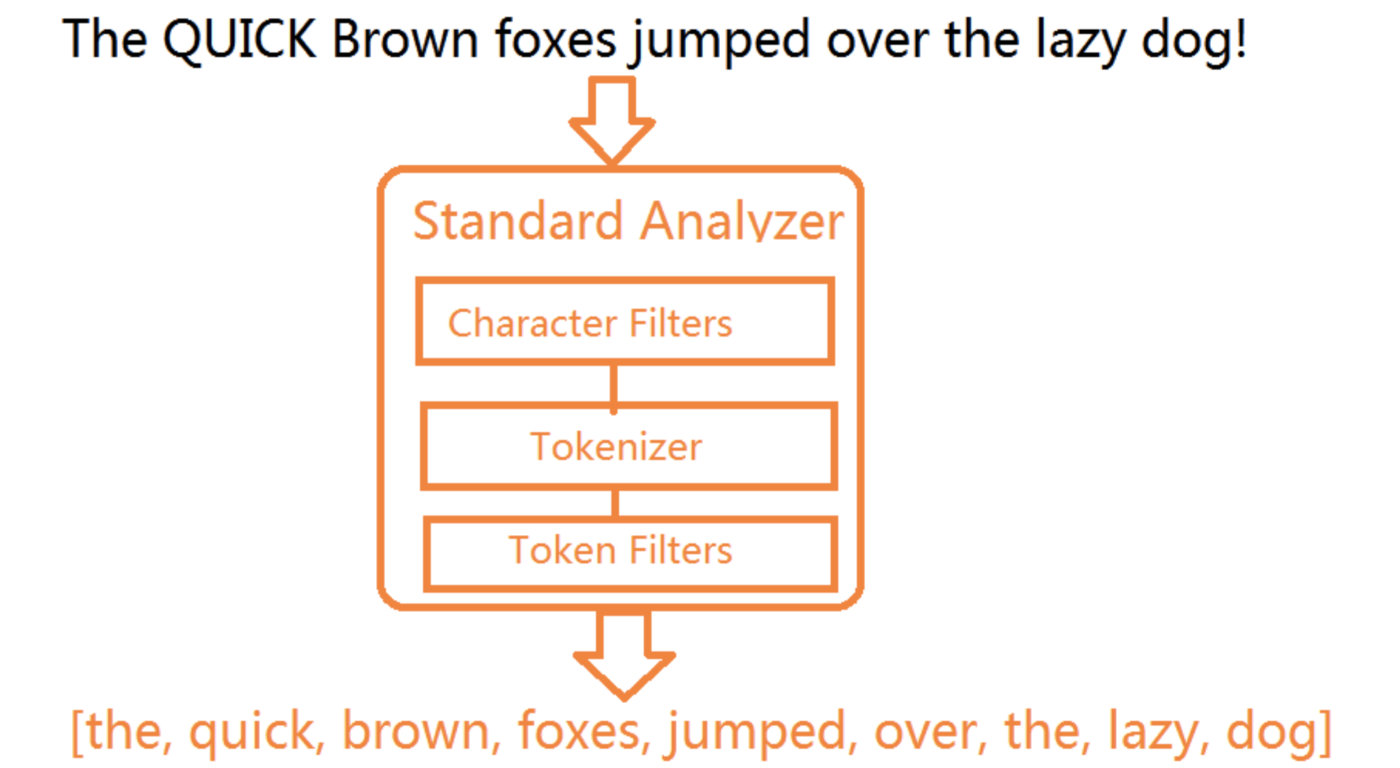
分词器是ES中专门处理分词的组件,英文为Analyzer,它的组成如下:
- Character Filters:针对原始文本进行处理,比如去除html标签
- Tokenizer:将原始文本按照一定规则切分为单词
- Token Filters:针对Tokenizer处理的单词进行再加工,比如转小写、删除或增新等处理
分词器调用顺序
Analyze API
ES提供了一个可以测试分词的API接口,方便验证分词效果,endpoint是_analyze
- 可以直接指定analyzer进行测试

- 可以直接指定索引中的字段进行测试
1 | POST test_index/doc |
- 可以自定义分词器进行测试
1 | POST _analyze |
预定义的分词器
ES自带的分词器有如下:
- Standard Analyzer
- 默认分词器
- 按词切分,支持多语言
- 小写处理
- Simple Analyzer
- 按照非字母切分
- 小写处理
- Whitespace Analyzer
- 空白字符作为分隔符
- Stop Analyzer
- 相比Simple Analyzer多了去除请用词处理
- 停用词指语气助词等修饰性词语,如the, an, 的, 这等
- Keyword Analyzer
- 不分词,直接将输入作为一个单词输出
- Pattern Analyzer
- 通过正则表达式自定义分隔符
- 默认是\W+,即非字词的符号作为分隔符
- Language Analyzer
- 提供了30+种常见语言的分词器
示例:停用词分词器
1 | POST _analyze |
结果
1 | { |
中文分词
- 难点
- 中文分词指的是将一个汉字序列切分为一个一个的单独的词。在英文中,单词之间以空格作为自然分界词,汉语中词没有一个形式上的分界符
- 上下文不同,分词结果迥异,比如交叉歧义问题
- 常见分词系统
安装ik中文分词插件
1 | # 在Elasticsearch安装目录下执行命令,然后重启es |
- ik测试 - ik_smart
1 | POST _analyze |
- ik测试 - ik_max_word
1 | POST _analyze |
- ik两种分词模式ik_max_word 和 ik_smart 什么区别?
- ik_max_word: 会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,中华人民,中华,华人,人民共和国,人民,人,民,共和国,共和,和,国国,国歌”,会穷尽各种可能的组合;
- ik_smart: 会做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,国歌”。
自定义分词
当自带的分词无法满足需求时,可以自定义分词,通过定义Character Filters、Tokenizer和Token Filters实现
Character Filters
- 在Tokenizer之前对原始文本进行处理,比如增加、删除或替换字符等
- 自带的如下:
- HTML Strip Character Filter:去除HTML标签和转换HTML实体
- Mapping Character Filter:进行字符替换操作
- Pattern Replace Character Filter:进行正则匹配替换
- 会影响后续tokenizer解析的position和offset信息
Character Filters测试
1 | POST _analyze |
Tokenizers
- 将原始文本按照一定规则切分为单词(term or token)
- 自带的如下:
- standard 按照单词进行分割
- letter 按照非字符类进行分割
- whitespace 按照空格进行分割
- UAX URL Email 按照standard进行分割,但不会分割邮箱和URL
- Ngram 和 Edge NGram 连词分割
- Path Hierarchy 按照文件路径进行分割
Tokenizers 测试
1 | POST _analyze |
Token Filters
- 对于tokenizer输出的单词(term)进行增加、删除、修改等操作
- 自带的如下:
- lowercase 将所有term转为小写
- stop 删除停用词
- Ngram 和 Edge NGram 连词分割
- Synonym 添加近义词的term
Token Filters测试
1 | POST _analyze |
自定义分词
自定义分词需要在索引配置中设定 char_filter、tokenizer、filter、analyzer等
自定义分词示例:
- 分词器名称:my_custom\
- 过滤器将token转为大写
1 | PUT test_index_1 |
1 | // java |
自定义分词器测试
1 | POST test_index_1/_analyze |
分词使用说明
分词会在如下两个时机使用:
- 创建或更新文档时(Index Time),会对相应的文档进行分词处理
- 查询时(Search Time),会对查询语句进行分词
- 查询时通过analyzer指定分词器
- 通过index mapping设置search_analyzer实现
- 一般不需要特别指定查询时分词器,直接使用索引分词器即可,否则会出现无法匹配的情况
分词使用建议
- 明确字段是否需要分词,不需要分词的字段就将type设置为keyword,可以节省空间和提高写性能
- 善用_analyze API,查看文档的分词结果
elasticsearch6.x倒排索引和分词
https://byte4sec.github.io/2019/05/06/elasticsearch6-x倒排索引和分词/
