privatevoidgrow(int minCapacity){ // overflow-conscious code int oldCapacity = elementData.length; int newCapacity = oldCapacity + (oldCapacity >> 1); if (newCapacity - minCapacity < 0) newCapacity = minCapacity; if (newCapacity - MAX_ARRAY_SIZE > 0) newCapacity = hugeCapacity(minCapacity); // minCapacity is usually close to size, so this is a win: elementData = Arrays.copyOf(elementData, newCapacity); }
3. 删除元素
需要调用 System.arraycopy() 将 index+1 后面的元素都复制到 index 位置上,该操作的时间复杂度为 O(N),可以看出 ArrayList 删除元素的代价是非常高的。
1 2 3 4 5 6 7 8 9 10
public E remove(int index){ rangeCheck(index); modCount++; E oldValue = elementData(index); int numMoved = size - index - 1; if (numMoved > 0) System.arraycopy(elementData, index+1, elementData, index, numMoved); elementData[--size] = null; // clear to let GC do its work return oldValue; }
privatevoidwriteObject(java.io.ObjectOutputStream s) throws java.io.IOException{ // Write out element count, and any hidden stuff int expectedModCount = modCount; s.defaultWriteObject();
// Write out size as capacity for behavioural compatibility with clone() s.writeInt(size);
// Write out all elements in the proper order. for (int i=0; i<size; i++) { s.writeObject(elementData[i]); }
if (modCount != expectedModCount) { thrownew ConcurrentModificationException(); } }
// Read in size, and any hidden stuff s.defaultReadObject();
// Read in capacity s.readInt(); // ignored
if (size > 0) { // be like clone(), allocate array based upon size not capacity ensureCapacityInternal(size);
Object[] a = elementData; // Read in all elements in the proper order. for (int i=0; i<size; i++) { a[i] = s.readObject(); } } } privatevoidwriteObject(java.io.ObjectOutputStream s) throws java.io.IOException{ // Write out element count, and any hidden stuff int expectedModCount = modCount; s.defaultWriteObject();
// Write out size as capacity for behavioural compatibility with clone() s.writeInt(size);
// Write out all elements in the proper order. for (int i=0; i<size; i++) { s.writeObject(elementData[i]); }
if (modCount != expectedModCount) { thrownew ConcurrentModificationException(); } }
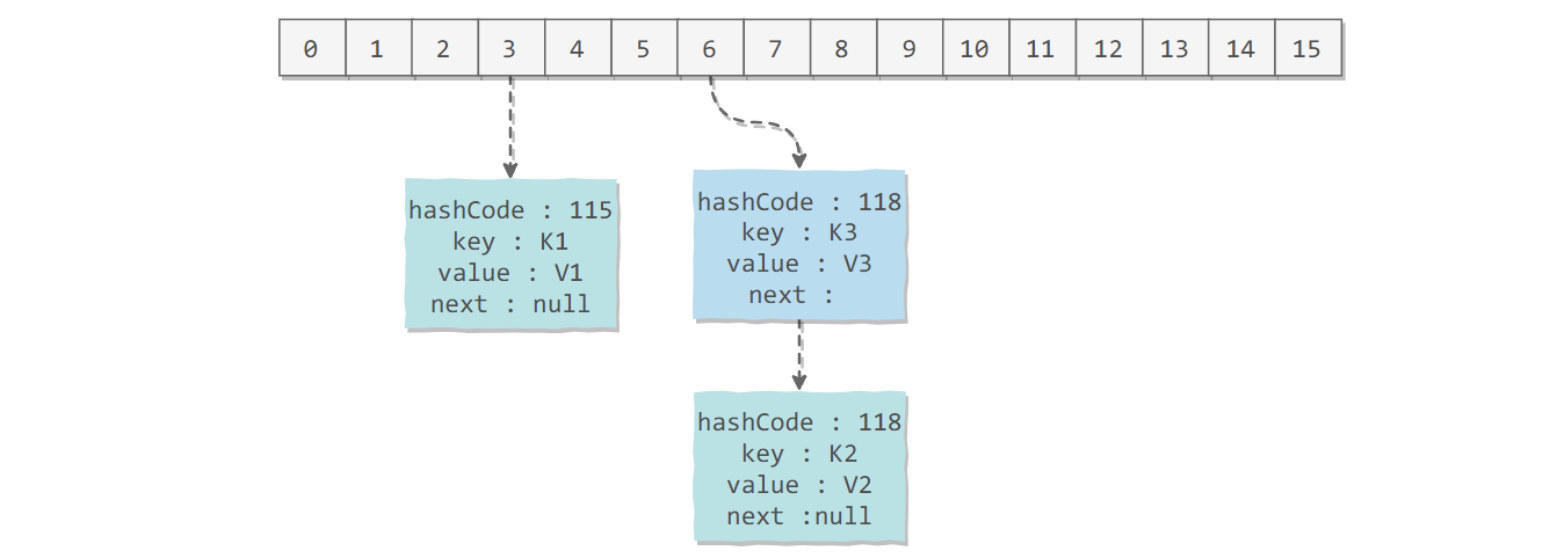
voidaddEntry(int hash, K key, V value, int bucketIndex){ if ((size >= threshold) && (null != table[bucketIndex])) { resize(2 * table.length); hash = (null != key) ? hash(key) : 0; bucketIndex = indexFor(hash, table.length); }
createEntry(hash, key, value, bucketIndex); }
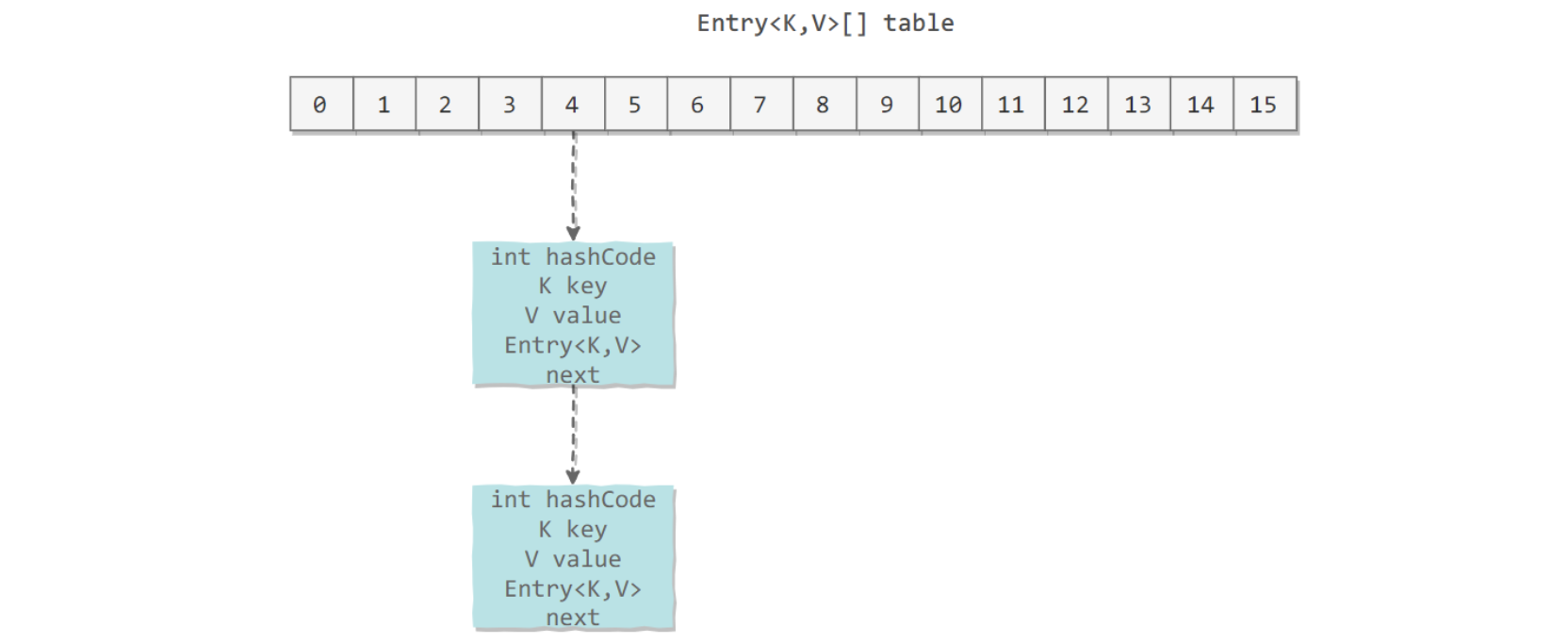
voidcreateEntry(int hash, K key, V value, int bucketIndex){ Entry<K,V> e = table[bucketIndex]; // 头插法,链表头部指向新的键值对 table[bucketIndex] = new Entry<>(hash, key, value, e); size++; } Entry(int h, K k, V v, Entry<K,V> n) { value = v; next = n; key = k; hash = h; }
4. 确定桶下标
很多操作都需要先确定一个键值对所在的桶下标。
1 2
int hash = hash(key); int i = indexFor(hash, table.length);
4.1 计算 hash 值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
finalinthash(Object k){ int h = hashSeed; if (0 != h && k instanceof String) { return sun.misc.Hashing.stringHash32((String) k); }
h ^= k.hashCode();
// This function ensures that hashCodes that differ only by // constant multiples at each bit position have a bounded // number of collisions (approximately 8 at default load factor). h ^= (h >>> 20) ^ (h >>> 12); return h ^ (h >>> 7) ^ (h >>> 4); } publicfinalinthashCode(){ return Objects.hashCode(key) ^ Objects.hashCode(value); }
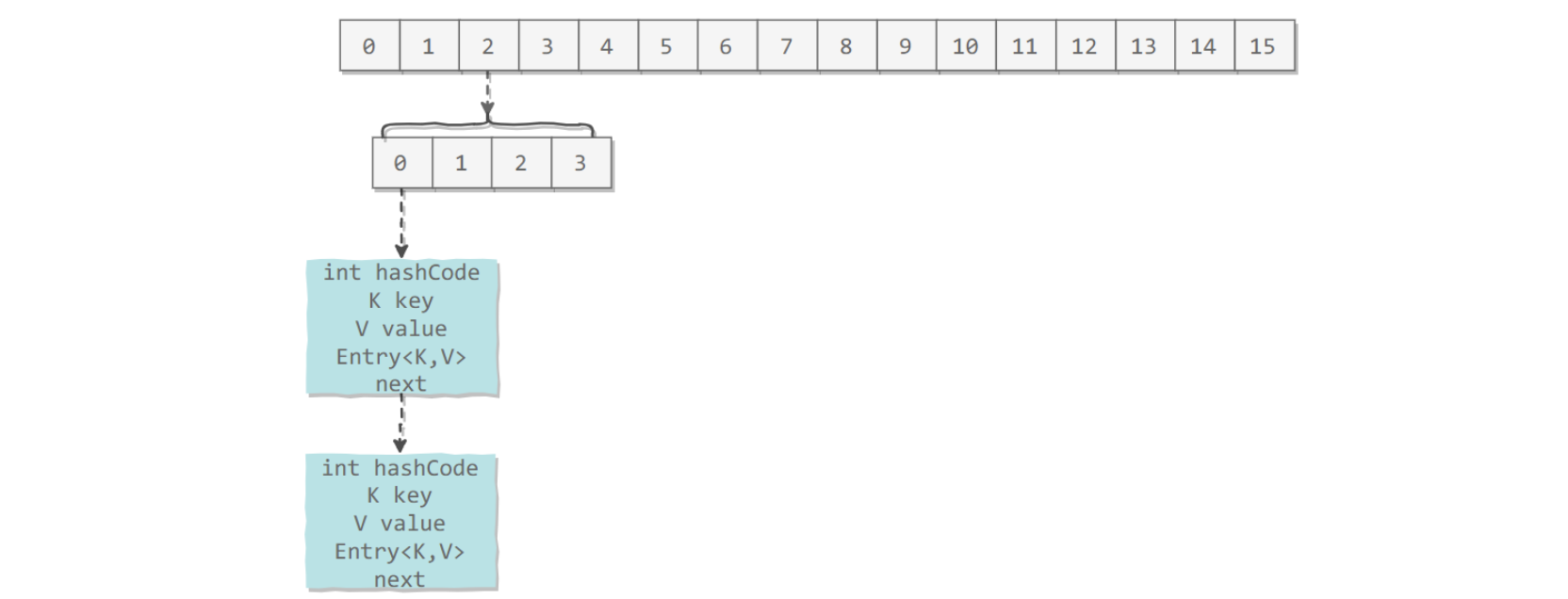
voidaddEntry(int hash, K key, V value, int bucketIndex){ Entry<K,V> e = table[bucketIndex]; table[bucketIndex] = new Entry<>(hash, key, value, e); if (size++ >= threshold) resize(2 * table.length); }
voidtransfer(Entry[] newTable){ Entry[] src = table; int newCapacity = newTable.length; for (int j = 0; j < src.length; j++) { Entry<K,V> e = src[j]; if (e != null) { src[j] = null; do { Entry<K,V> next = e.next; int i = indexFor(e.hash, newCapacity); e.next = newTable[i]; newTable[i] = e; e = next; } while (e != null); } } }
staticfinalinttableSizeFor(int cap){ int n = cap - 1; n |= n >>> 1; n |= n >>> 2; n |= n >>> 4; n |= n >>> 8; n |= n >>> 16; return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1; }
/** * Number of unsynchronized retries in size and containsValue * methods before resorting to locking. This is used to avoid * unbounded retries if tables undergo continuous modification * which would make it impossible to obtain an accurate result. */ staticfinalint RETRIES_BEFORE_LOCK = 2;
publicintsize(){ // Try a few times to get accurate count. On failure due to // continuous async changes in table, resort to locking. final Segment<K,V>[] segments = this.segments; int size; boolean overflow; // true if size overflows 32 bits long sum; // sum of modCounts long last = 0L; // previous sum int retries = -1; // first iteration isn't retry try { for (;;) { // 超过尝试次数,则对每个 Segment 加锁 if (retries++ == RETRIES_BEFORE_LOCK) { for (int j = 0; j < segments.length; ++j) ensureSegment(j).lock(); // force creation } sum = 0L; size = 0; overflow = false; for (int j = 0; j < segments.length; ++j) { Segment<K,V> seg = segmentAt(segments, j); if (seg != null) { sum += seg.modCount; int c = seg.count; if (c < 0 || (size += c) < 0) overflow = true; } } // 连续两次得到的结果一致,则认为这个结果是正确的 if (sum == last) break; last = sum; } } finally { if (retries > RETRIES_BEFORE_LOCK) { for (int j = 0; j < segments.length; ++j) segmentAt(segments, j).unlock(); } } return overflow ? Integer.MAX_VALUE : size; }